1. What is RAG ?
Retrieval Augmented Generation (RAG), is a method where you have a foundation model, and you have a library of personal documents – this can be unstructured data in any format. Now your goal is for answering some questions from your persona library of docs, with the help of LLM. Enter RAG – instead of fine-tuning the foundation LLM which is cost and time-consuming, you instead create embeddings from your personal suite of documents, and store it in some database (vector DB or traditional DB that allows storing embedding vectors), and while prompting the LLM, you give all context necessary from this vector database containing information from your documents. It’s like an open-book test, the LLM has its foundation knowledge, you give additional context with your necessary information, now can this LLM + Personal Document Library stored in a DB help answer your questions. This set up is called RAG.
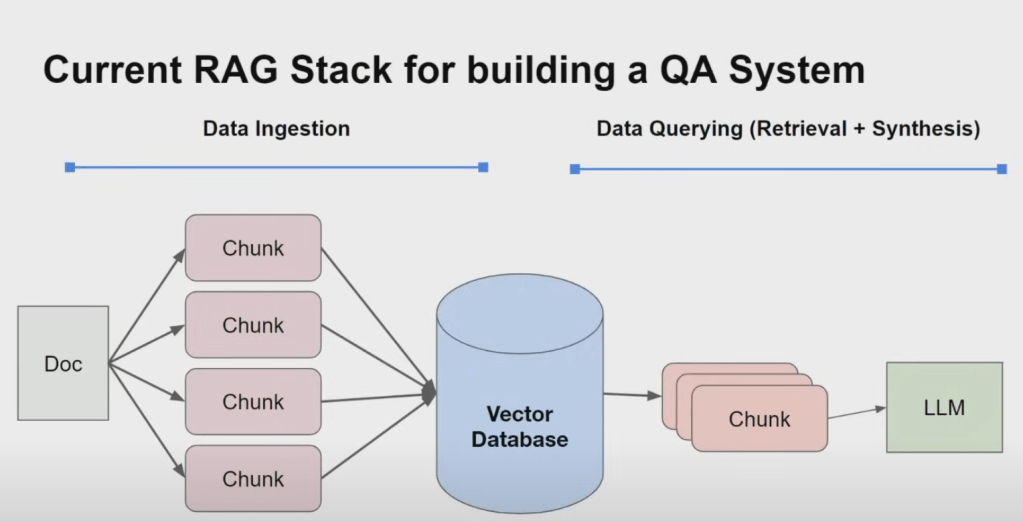
Let’s take an example:
Imagine you have a smart assistant that knows a lot, like a teacher, but isn’t familiar with your specific class notes or the personal projects you’ve worked on. You want this assistant to help you answer questions about your own materials—things it’s never actually seen or studied before.
This is where Retrieval-Augmented Generation (RAG) comes in. Instead of training the assistant on your notes from scratch (which would take tons of time and resources), you can let it access your notes whenever needed, like an “open-book” exam. Here’s how it works:
- Set up Your Library of Knowledge: First, you collect all the documents or files you want this assistant to use—emails, research papers, reports, even unstructured notes. Think of it like building a personal library.
- Make Your Notes Searchable: Next, you “tag” these documents so they’re easily searchable. In technical terms, this means turning each document into an “embedding” (a fancy way of making sure each document can be quickly matched to a relevant question). You then store these embeddings in a searchable database.
- Let the Assistant Look Up Answers: When you ask the assistant a question, it doesn’t just guess based on its general knowledge. Instead, it first “looks up” your documents, finds the most relevant information from your library, and combines it with its own knowledge to give you a much more accurate, context-rich answer.
Here’s a real-life analogy:
Imagine you’re preparing for an interview and have tons of notes and specific information about the company. Instead of memorizing every detail, you organize these notes so that, when asked a question, you can quickly find the exact information you need. Your brain is like the foundational knowledge, and your notes are like your personal library. By combining these, you can give well-informed answers without having to remember everything verbatim.
RAG works similarly: it leverages a pre-trained model’s general knowledge, like your brain’s foundational knowledge, but “looks up” relevant personal information whenever it needs it. This approach gives you the best of both worlds: you save the time and expense of training the assistant on your whole library while still getting responses tailored to your unique knowledge base.
2. Core Components of a RAG System: A Breakdown
1. Data Ingestion: Preparing Information for Access
The first crucial stage in any RAG pipeline is data ingestion. This involves:
- Gathering data from various sources: RAG systems can work with a diverse range of data sources, including unstructured text documents, SQL databases, knowledge graphs, and more.
- Preprocessing the data: This may involve tasks like cleaning the text, removing irrelevant information, and structuring the data into a format suitable for the RAG system.
- Chunking the data: Large documents are typically divided into smaller chunks, making them more manageable for indexing and retrieval. The choice of chunk size can significantly impact performance, as discussed in our previous conversation about table stakes techniques.
2. Data Querying: Retrieval and Synthesis
The heart of a RAG system lies in its ability to effectively retrieve relevant information and then use that information to generate a coherent and informative response. This data querying process can be further broken down into two main components:
- Retrieval: This stage focuses on identifying the most relevant chunks of information from the ingested data that correspond to a user’s query. The sources highlight several approaches to retrieval, including:
- Semantic Search Using Vector Databases: Text chunks are embedded into a vector space using embedding models. When a user poses a query, it’s also embedded into the same vector space, and the system retrieves the chunks closest to the query in that space. The sources mention vector databases like Chroma and Pinecone as tools for managing these embeddings.
- Metadata Filtering: Structured metadata associated with text chunks can be used to refine retrieval. This allows for combining semantic search with structured queries, leading to more precise results.
- Hybrid Search: Combining different retrieval methods, such as keyword-based search and semantic search, can further enhance retrieval effectiveness.
- Advanced Retrieval Methods: The sources discuss more sophisticated techniques like small-to-big retrieval and embedding references, which aim to improve retrieval precision and overcome limitations of traditional methods.
- Synthesis: Once the relevant information has been retrieved, it’s passed to a large language model (LLM) for response generation. The LLM uses the retrieved context to:
- Understand the user’s query: The LLM processes the query and the retrieved information to grasp the user’s intent and the context of the question.
- Synthesize a coherent response: The LLM generates a response that answers the user’s query, drawing upon the provided context and its own knowledge.
Going Beyond the Basics: Agents and Fine-Tuning
Building production-ready RAG applications often requires going beyond these fundamental components. Agentic methods can be incorporated to enhance the reasoning and decision-making capabilities of RAG systems, allowing them to tackle more complex tasks and queries.
Additionally, fine-tuning techniques can be applied to various stages of the RAG pipeline to further improve performance. This could involve:
- Fine-tuning embedding models: Optimizing embeddings to better represent the specific data and tasks relevant to the application.
- Fine-tuning LLMs: Training the LLM on synthetic datasets to enhance its ability to synthesize responses, reason over retrieved information, and generate structured outputs.
By carefully considering and implementing these additional strategies, developers can create RAG systems that are more robust, accurate, and capable of handling a wider range of real-world applications.
3. Challenges in Building Production-Ready RAG Systems
Response Quality Challenges
- Retrieval Issues: The sources point to poor retrieval as a significant challenge. If the retrieval stage doesn’t return relevant chunks from the vector database, the LLM won’t have the right context for generating accurate responses. Issues include:
- Low Precision: Not all retrieved chunks are relevant, leading to hallucinations and “loss in the middle” problems, where crucial information in the middle of the context window gets overlooked by the LLM.
- Low Recall: The retrieved set of information might not contain all the necessary information to answer the question, possibly due to insufficient top-K values.
- Outdated Information: The retrieved information might be out of date, leading to inaccurate responses.
- LLM Limitations: The sources acknowledge limitations inherent to LLMs, which contribute to response quality challenges. These include:
- Hallucination: The LLM might generate inaccurate information not supported by the retrieved context.
- Irrelevance: The LLM’s response might not directly address the user’s query.
- Toxicity and Bias: The LLM might generate responses that are harmful or biased, reflecting biases present in the training data.
RAG Pipeline Challenges
Beyond response quality, the sources identify various challenges throughout the RAG pipeline:
- Data Ingestion and Optimization:
- Beyond Raw Text: The sources suggest exploring storage of additional information beyond raw text chunks in the vector database to enhance context and retrieval.
- Chunk Size Optimization: Experimenting with chunk sizes is crucial, as it significantly impacts retrieval and synthesis performance. Simply increasing the number of retrieved tokens doesn’t always improve performance.
- Embedding Representations: Pre-trained embedding models might not be optimal for specific tasks or datasets. The sources propose optimizing embedding representations for improved retrieval performance.
- Retrieval Algorithms: Relying solely on retrieving the top-K most similar elements from the vector database often proves insufficient. The sources recommend exploring more advanced retrieval techniques.
- Limited Reasoning Capabilities: The sources highlight the limitation of basic RAG systems in handling complex tasks requiring multi-step reasoning or advanced analysis, as they primarily rely on the LLM for synthesis at the end of the retrieval process.
- Fine-tuning Requirements: The sources emphasize the need to fine-tune various components of the RAG pipeline for optimal performance, including:
- Embedding Fine-tuning: Fine-tuning embeddings on a synthetic dataset generated from the data corpus can improve retrieval accuracy. This can be achieved by fine-tuning either the base model or an adapter on top of it.
- LLM Fine-tuning: Fine-tuning smaller LLMs using a synthetic dataset generated by a larger, more capable LLM can enhance response quality, reasoning ability, and structured output generation.
A task-specific approach and robust performance evaluation to good identify bottlenecks and prioritize improvement strategies across the RAG pipeline.
4. Four Table Stakes Methods for Enhancing RAG Performance
The following techniques offer significant performance improvements with relatively straightforward implementations. Here are four key table stakes methods to consider:
1. Chunk Size Tuning
The process of dividing a text corpus into smaller units, known as chunks, is fundamental to RAG systems. However, the size of these chunks significantly impacts retrieval and synthesis performance. The sources highlight the importance of chunk size tuning as a critical step in optimizing RAG systems.
- Impact on Retrieval: Chunk size directly influences the embedding representation of text units and the subsequent retrieval process. Smaller chunks tend to focus on more specific concepts, allowing the embedding model to capture their semantic meaning more effectively, potentially leading to more precise retrieval. However, overly small chunks can result in fragmentation and loss of context.
- Impact on Synthesis: Larger chunks provide the LLM with more context for generating comprehensive responses. However, the sources warn against excessively large chunks, as they can lead to the “loss in the middle” problem where information in the middle of a chunk is less likely to be effectively utilized by the LLM.
- Finding the Optimal Chunk Size: The optimal chunk size depends on the specific dataset and task. Experimentation and evaluation, as discussed in our previous conversation, are crucial for determining the chunk size that yields the best performance for a given RAG application.
2. Metadata Filtering
This technique leverages structured information associated with text chunks to refine the retrieval process.
- Enriching Text Chunks with Metadata: Metadata refers to structured data that provides additional context about the text chunks. Examples include:
- Page number within a document
- Document title
- Summaries of adjacent chunks
- Hallucinated questions that the chunk might answer
- Integration with Vector Database Filters: Metadata filtering often integrates with the filtering capabilities of vector databases. By combining semantic search with metadata filters, the system can narrow down the search space more effectively.
- Example: Imagine a user asks a question about risk factors mentioned in a company’s financial report from a specific year. By using metadata filters to specify the year, the system can avoid retrieving information from reports of other years, even if those reports contain semantically similar language.
3. Hybrid Search
Many vector databases offer hybrid search capabilities, which combine keyword-based search with vector search. This approach can significantly enhance retrieval performance.
- Benefits of Keyword Search: Keyword search excels at retrieving documents that contain specific terms, providing a high degree of precision for queries that are well-defined by keywords.
- Strengths of Vector Search: Vector search captures semantic similarity between queries and documents, enabling the retrieval of relevant information even when exact keywords are not present in the query.
- Synergistic Combination: By combining these two approaches, hybrid search leverages the strengths of both keyword and vector search. This leads to improved retrieval performance, particularly for queries that can benefit from both precise keyword matching and semantic understanding.
4. Better Pruning Techniques
Pruning refers to techniques that aim to reduce the number of text chunks considered during retrieval, leading to more efficient processing and potentially higher retrieval precision.
- Moving Beyond Even Chunk Splitting: Traditional RAG systems often split documents into chunks of equal size. However, this approach can be suboptimal as it does not consider the inherent structure or information density of the text.
- Exploring Alternative Pruning Strategies: Better pruning techniques involve adopting more sophisticated strategies that take into account factors like sentence boundaries, topic segmentation, or information saliency within the text. This allows the system to create chunks that are more meaningful and representative of the underlying content, leading to improved retrieval performance.
Importance of Table Stakes Methods:
Prioritize these table stakes methods before exploring more advanced techniques like agents or fine-tuning. These basic optimizations often yield significant performance improvements with relatively low implementation complexity. By addressing these fundamental aspects of RAG systems, developers can establish a strong foundation for building more effective and robust RAG applications.
5. Impact of Chunk Size on RAG System Performance
- Retrieval Performance:
- Precision: Smaller chunk sizes generally lead to higher precision in retrieval. When chunks are smaller, they are more likely to contain specific, focused pieces of information. This makes it easier for the embedding model to accurately capture the semantic meaning of each chunk and return highly relevant chunks for a given query.
- Recall: Conversely, larger chunk sizes can potentially improve recall, as they might encompass a broader range of information relevant to a query. However, this comes at the risk of reduced precision due to the inclusion of irrelevant information within the chunk.
- Synthesis Performance:
- Loss in the Middle Problem: The sources highlight the “loss in the middle” problem, where LLMs tend to prioritize information at the beginning and end of their context window, potentially overlooking crucial information located in the middle. With larger chunk sizes, this problem becomes more pronounced, as relevant information might get buried in the middle of a long chunk, leading to less accurate or incomplete responses.
- Context Window Limitations: LLMs have limited context windows, restricting the amount of information they can process at once. If chunk sizes are too large, the LLM might not be able to process the entire chunk, potentially truncating important information and hindering response quality.
- Optimal Chunk Size:
- Data-Specific Optimization: The sources stress that there is no universally optimal chunk size. The ideal chunk size depends on factors such as the nature of the dataset (e.g., document length, information density), the complexity of the queries, and the specific LLM being used. Experimentation and careful evaluation are crucial for determining the most effective chunk size for a given RAG system.
Key Considerations for Chunk Size Optimization:
- Balance Precision and Recall: The choice of chunk size involves a trade-off between precision and recall. Smaller chunks enhance precision but might sacrifice recall, while larger chunks improve recall at the risk of lower precision.
- Mitigate Loss in the Middle: Using smaller chunk sizes can help address the “loss in the middle” problem by reducing the likelihood of crucial information being buried within a large chunk.
- Respect Context Window Limits: Choose chunk sizes that are compatible with the context window limitations of the LLM being used to avoid information truncation and ensure comprehensive processing of retrieved information.
In summary, chunk size significantly impacts both retrieval and synthesis performance in RAG systems. Carefully optimizing chunk size, based on data characteristics and task requirements, is essential for achieving a balance between precision, recall, and effective utilization of the LLM’s capabilities.
6. The Power of Metadata Filtering in RAG Systems
Metadata filtering is a powerful technique that can significantly enhance the precision of retrieval in RAG applications. It achieves this by adding structured context to the text chunks stored in the vector database, which allows for more targeted and accurate retrieval of relevant information.
Metadata is a structured JSON dictionary containing additional information about each text chunk. This information can include various attributes such as:
- Page Number: Indicating the location of the chunk within a document.
- Document Title: Providing context about the overall theme of the document.
- Summary of Adjacent Chunks: Offering a glimpse into the surrounding information.
- Hallucinated Questions: Imagining potential questions that the chunk might answer.
These metadata attributes can be leveraged during the retrieval process to improve the accuracy of results. Here’s how:
1. Combining Semantic Search with Structured Queries
Instead of relying solely on semantic similarity between the query and the text chunks, metadata filtering allows for the incorporation of structured queries, similar to using a “WHERE” clause in a SQL statement. This enables the system to narrow down the search space and focus on chunks that meet specific criteria defined by the metadata.
Example: If the user asks about “risk factors in 2021” from an SEC 10-Q document, the system can use metadata filtering to specifically target chunks from the year 2021. This prevents the retrieval of irrelevant information from other years, drastically improving precision.
2. Reducing Reliance on Pure Semantic Matching
Pure semantic search can be unreliable, especially when dealing with complex queries or documents with nuanced language. Metadata filtering helps mitigate this by providing additional signals for relevance beyond just the raw text.
Example: When searching for information about a specific company, metadata filters can be used to prioritize chunks from documents explicitly mentioning that company, even if the query itself doesn’t explicitly state the company name. This helps in retrieving highly relevant information that might have been missed by relying solely on semantic similarity.
3. Integrating with Vector Database Capabilities
Modern vector databases like Chroma and Pinecone often have built-in support for metadata filtering. This allows for seamless integration of metadata into the retrieval process, further enhancing the system’s ability to pinpoint relevant information.
Benefits of Metadata Filtering:
- Improved Precision: By narrowing down the search space and focusing on chunks with relevant metadata, metadata filtering significantly reduces the chances of retrieving irrelevant information.
- Enhanced Response Quality: More precise retrieval leads to the LLM receiving more accurate and relevant context, resulting in higher-quality responses that are more likely to address the user’s query effectively.
- Efficient Retrieval: By reducing the number of irrelevant chunks that need to be processed, metadata filtering can contribute to faster retrieval times, improving the overall efficiency of the RAG system.
In conclusion, metadata filtering plays a crucial role in enhancing the precision of retrieval in RAG applications. By leveraging structured information about text chunks, it enables more targeted retrieval, improves response quality, and contributes to the development of more robust and production-ready RAG systems.
7. Advanced Retrieval Methods for Enhancing RAG Systems
Beyond the foundational “table stakes” techniques, several advanced retrieval methods can further boost the performance of RAG systems. These methods often draw inspiration from traditional Information Retrieval (IR) principles while also incorporating novel concepts tailored to the unique characteristics of LLM-powered applications. Let’s examine some of these advanced techniques:
1. Reranking Retrieved Chunks
Reranking is a traditional IR concept that remains relevant in the context of RAG systems. Reranking involves refining the initial list of retrieved chunks based on additional criteria beyond the initial similarity scores from the vector database.
- Motivation: The initial retrieval stage, often relying on top-k nearest neighbor search in the vector space, may not always produce the most optimal ranking of relevant chunks. Factors such as the presence of irrelevant information within a retrieved chunk or the overall coherence of the retrieved set may not be fully captured by the initial similarity scores.
- Reranking Approaches: Various techniques can be employed for reranking, including:
- LLM-Based Reranking: Using an LLM to assess the relevance and coherence of the retrieved chunks in relation to the query.
- Graph-Based Reranking: Constructing a graph where nodes represent chunks and edges represent relationships between chunks (e.g., semantic similarity, co-occurrence). Reranking can then be performed by analyzing the graph structure.
- Benefits: Reranking can improve the quality of the context provided to the LLM for synthesis, leading to more accurate and relevant responses.
2. Recursive Retrieval
Recursive retrieval, is a technique specifically developed within the context of LLM-based applications. Recursive retrieval addresses situations where the initial retrieved set of chunks may not contain all the necessary information to answer a complex query.
- Addressing Information Gaps: In complex scenarios, a single retrieval step might not suffice. Certain pieces of information might only be discoverable after understanding the context provided by initially retrieved chunks.
- Iterative Retrieval Process: Recursive retrieval involves multiple retrieval steps. The information gleaned from the initial retrieval is used to refine the query and trigger subsequent retrieval steps, iteratively expanding the knowledge base until sufficient context is gathered.
- Example: Consider a query requiring information from multiple sources or involving a chain of reasoning. Recursive retrieval enables the system to start with an initial set of clues, follow those clues to additional sources, and progressively gather the necessary information to answer the query.
3. Small-to-Big Retrieval
Small-to-big retrieval is a technique that optimizes both retrieval precision and the comprehensiveness of context provided to the LLM.
- Challenge of Large Chunks: Embedding large chunks of text can dilute the semantic representation, as irrelevant information within the chunk can influence the embedding vector. This can lead to less precise retrieval. Conversely, synthesizing over large chunks risks the “loss in the middle” problem.
- Granular Retrieval, Expanded Synthesis: Small-to-big retrieval addresses this challenge by:
- Embedding at a Fine-Grained Level: Text is embedded at a more granular level (e.g., sentence level) to capture semantic meaning more precisely and enhance retrieval accuracy.
- Expanding Context During Synthesis: During synthesis, the system expands the context window to include not only the retrieved small chunks but also their surrounding context within the original document. This provides the LLM with a more comprehensive view for generating responses.
4. Embedding References Instead of Raw Text
Embedding references to parent chunks instead of the raw text of smaller chunks is a technique for improving retrieval performance.
- Optimizing Embedding for Retrieval: Directly embedding the raw text of a smaller chunk (e.g., a sentence) might not be optimal for retrieval. The embedding might not effectively capture the chunk’s relevance in the broader context of its parent chunk or document.
- Embedding References: Instead of embedding the raw text, the system can embed a reference that points to the parent chunk. This reference can include:
- The parent chunk’s identifier
- Metadata about the parent chunk (e.g., title, summary)
- Benefits: Embedding references allows the system to:
- Focus on Retrieving Relevant Parent Chunks: The embedding is tailored to represent the parent chunk’s relevance to the query.
- Access More Context During Synthesis: Once the relevant parent chunks are retrieved, the system has access to the full context of those chunks for synthesis, ensuring the LLM has sufficient information.
5. Incorporating Agents for Advanced Reasoning
Agents are a powerful approach to enhance RAG systems, particularly for handling complex queries that require multi-step reasoning.
- Limitations of Traditional RAG: Conventional RAG systems primarily focus on question answering based on retrieved chunks. They may struggle with queries involving intricate reasoning, information gathering from multiple sources, or the synthesis of insights from multiple documents.
- Modeling Documents as Tools: Agent-based approaches treat documents not just as text chunks but as collections of tools. These tools can include capabilities like:
- Summarization: Summarizing the content of a document.
- Targeted QA: Answering specific questions about the document.
- Retrieval and Tool Use: The agent combines retrieval mechanisms to identify relevant documents (or tools) and then employs these tools to perform actions, gather information, and reason through the query.
6. Fine-tuning Embeddings and LLMs
Fine-tuning is a potent technique for optimizing specific components within a RAG pipeline, including both embeddings and LLMs.
- Fine-tuning Embeddings: Pre-trained embedding models may not be optimally tuned for a specific dataset or task. Fine-tuning the embedding model on data relevant to the RAG application can lead to more accurate retrieval.
- Fine-tuning LLMs: Fine-tuning the LLM used for synthesis can improve its ability to generate responses that are:
- More coherent
- Better aligned with the specific domain or task
- More capable of structured output
Key Considerations for Advanced Retrieval Methods:
While these advanced retrieval techniques offer substantial potential for improving RAG performance, it’s essential to consider:
- Task Specificity: The effectiveness of a particular method depends heavily on the specific task and dataset.
- Complexity and Cost: Advanced methods often involve higher computational complexity and cost compared to basic optimizations.
- Evaluation and Iteration: Thorough evaluation is crucial to determine the impact of these techniques and guide iterative refinement.
By carefully selecting and implementing appropriate advanced retrieval methods, developers can create RAG systems that are more accurate, efficient, and capable of handling complex knowledge access tasks.
8. Understanding Small-to-Big Retrieval in RAG
Small-to-big retrieval is an advanced retrieval method designed to enhance the performance of Retrieval-Augmented Generation (RAG) systems. This technique aims to address the limitations of embedding and synthesizing over large text chunks by strategically using smaller chunks for retrieval and then expanding to larger chunks for synthesis.
Here’s a breakdown of the process:
- Embedding at a Granular Level: Instead of embedding large text chunks, small-to-big retrieval advocates for embedding text at a more granular level, such as sentence level or even smaller units. This allows for more precise capture of the semantic meaning of individual pieces of information, making it easier to retrieve highly relevant chunks in response to a query.
- Expanding the Window During Synthesis: Once the relevant smaller chunks are retrieved based on their embeddings, the system expands the context window during the synthesis stage. This involves fetching the larger parent chunks that contain the retrieved smaller chunks, providing the LLM with a broader context for generating a comprehensive and accurate response.
Advantages of Small-to-Big Retrieval:
- Improved Retrieval Precision: By embedding smaller chunks, the system can better pinpoint the most relevant pieces of information related to the user’s query, leading to higher retrieval precision. This is because smaller chunks are more likely to focus on specific concepts or facts, allowing the embedding model to capture their semantic meaning more effectively.
- Mitigation of “Loss in the Middle” Problem: As discussed in our previous conversation, the “loss in the middle” problem arises when LLMs prioritize information at the edges of their context window, potentially overlooking crucial information in the middle of large chunks. Small-to-big retrieval helps address this by initially retrieving based on smaller units, ensuring that key information is not buried within a larger chunk and overlooked during the retrieval stage.
- Optimized Top-K Retrieval: With small-to-big retrieval, the system can effectively operate with smaller top-K values during the initial retrieval phase. This is because the retrieval is focused on smaller units, leading to higher precision in the retrieved set. The subsequent expansion to larger chunks during synthesis ensures that the LLM still has access to a sufficient amount of context for generating comprehensive responses.
Example:
Imagine a user asks a question about a specific event described in a historical document. Using small-to-big retrieval:
- The system would first retrieve sentences or smaller segments related to the event based on their embeddings.
- Once these relevant smaller units are identified, the system would then expand to retrieve the larger paragraphs or sections containing those sentences, providing the LLM with a broader historical context surrounding the event.
Variations of Small-to-Big Retrieval:
A related idea is where instead of embedding the raw text of smaller chunks, the system embeds references to their parent chunks. This can involve embedding summaries of the parent chunks, questions that the parent chunks answer, or other representative information. This approach aims to improve retrieval performance by focusing on embedding information that is specifically tailored for retrieval purposes while still providing the LLM with access to the full context of the parent chunk during synthesis.
In conclusion, the small-to-big retrieval strategy offers a refined approach to retrieval in RAG systems. It leverages the granularity of smaller chunks for precise retrieval while ensuring that the LLM has access to sufficient context from larger chunks for comprehensive response generation. This method contributes to enhanced precision, mitigates limitations associated with large chunk processing, and ultimately leads to more effective and robust RAG applications.
9. Fine-Tuning Methods for RAG Systems
Fine-tuning is a potent technique for enhancing the performance of specific components within a RAG pipeline. Fine-tuning involves adjusting the parameters of a model, either the embedding model or the LLM itself, to better align with the specific characteristics of the dataset and the desired task. Let’s explore the fine-tuning methods discussed in the sources:
1. Fine-Tuning Embeddings
Rationale: Pre-trained embedding models, while providing a general representation of semantic meaning, might not be optimally tailored to the specific data used in a RAG application. This can lead to suboptimal retrieval performance, as the embedding vectors might not accurately reflect the relevance of text chunks to specific queries.
Objective: Fine-tuning the embedding model aims to refine the embedding vectors so that they better capture the semantic relationships within the context of the RAG application’s dataset. This leads to more precise retrieval of relevant information when responding to user queries.
Process:
- Generate Synthetic Query Data: The sources suggest using LLMs to generate synthetic queries from the raw text chunks within the RAG system’s knowledge base. This creates a dataset of query-chunk pairs that represent the kind of queries the system is expected to handle.
- Fine-Tune Using the Synthetic Data: The embedding model is then fine-tuned using this synthetic dataset. The fine-tuning process adjusts the model’s parameters to minimize the distance between the embedding vectors of relevant query-chunk pairs.
Methods:
- Fine-Tuning the Base Model: This involves adjusting the weights of the entire pre-trained embedding model. While potentially yielding the best performance, this method requires significant computational resources.
- Fine-Tuning an Adapter: An alternative approach involves adding a small, trainable adapter layer on top of the pre-trained embedding model. This adapter is fine-tuned, leaving the base model’s weights unchanged. This method is computationally less demanding and allows for preserving the general knowledge captured by the pre-trained model.
Benefits:
- Improved Retrieval Precision: Fine-tuned embeddings result in more accurate retrieval of relevant chunks, leading to more accurate and relevant responses from the RAG system.
- Reduced Need for Extensive Re-Indexing: Fine-tuning an adapter, as opposed to the entire base model, allows for updating the embedding representations without having to re-index the entire document corpus, saving time and computational effort.
2. Fine-Tuning LLMs
Rationale: The LLM responsible for synthesizing responses in a RAG system might benefit from fine-tuning to better align with the specific requirements of the application.
Objective: Fine-tuning the LLM can improve its ability to generate responses that are:
- More Coherent: Ensuring the generated text flows smoothly and logically.
- Domain-Specific: Tailoring the responses to the specific domain or topic of the RAG application.
- Structured Output: Producing responses in a desired format, such as bullet points, tables, or code.
Process:
- Data Generation Using a Powerful LLM: The sources propose generating a synthetic dataset using a more powerful LLM (e.g., GPT-4). This dataset would consist of examples of desired outputs for various inputs, effectively showcasing the desired response style and level of reasoning.
- Distillation into a Weaker LLM: The weaker LLM used in the RAG system (e.g., GPT-3.5 Turbo) is then fine-tuned using this synthetic dataset. This process distills the knowledge and capabilities of the larger model into the smaller one, improving its performance without the computational overhead of using the larger model directly.
Benefits:
- Enhanced Response Quality: Fine-tuning leads to more coherent, relevant, and informative responses.
- Improved Reasoning Capabilities: The LLM becomes better at following logical steps and drawing inferences from the retrieved context.
- Structured Output Generation: The LLM can be trained to generate responses in specific formats, making the output more useful and actionable.
Key Considerations for Fine-Tuning:
- Computational Resources: Fine-tuning, particularly for large models, can be computationally intensive. Access to sufficient computing power is essential.
- Data Quality: The quality of the data used for fine-tuning is crucial. Noisy or biased data can negatively impact the model’s performance.
- Overfitting: Care must be taken to avoid overfitting the model to the fine-tuning data, which would reduce its ability to generalize to new inputs.
By strategically applying fine-tuning techniques, developers can enhance the precision of retrieval, improve the quality of responses, and create more powerful and versatile RAG systems.
10. Agentic Methods for RAG: Moving Beyond Simple Retrieval and Generation
There is this more advanced and intriguing concept: using agents to enhance RAG pipelines. This approach goes beyond simply retrieving relevant information and generating responses; it involves incorporating reasoning and decision-making capabilities into the system.
Agents in RAG: Key Ideas
- Multi-Document Agents: The sources introduce the idea of treating documents not just as collections of text chunks, but as agents equipped with specialized tools. These tools could include:
- Summarization Tools: Allowing the agent to concisely summarize the content of the document.
- QA Tools: Enabling the agent to answer specific factual queries about the document.
- Retrieval of Tools: In a scenario with numerous documents, each represented as an agent with multiple tools, efficient retrieval becomes crucial. Similar to retrieving relevant text chunks, the system would need to identify the most appropriate agent and tool for a given query.
- Agent-Driven Reasoning and Action: Unlike traditional RAG, where the LLM primarily focuses on synthesizing a response based on retrieved text, an agent-based approach empowers the LLM to reason about the query, select the most relevant tools, and execute actions using those tools.
Why Agents? Limitations of Traditional RAG
Conventional RAG systems, while effective for certain tasks, encounter limitations when faced with complex queries or the need for multi-step reasoning.
- Constrained by Retrieval Quality: In traditional RAG, the LLM’s ability to generate a comprehensive response is heavily dependent on the quality of the retrieved information. If the retrieval stage fails to identify all the necessary pieces of information, the LLM might struggle to provide a complete and accurate answer.
- Limited to Question Answering: While RAG excels at question answering, it might not be as effective for tasks that demand more complex analysis, such as comparing multiple documents, synthesizing information from various sources, or performing multi-step reasoning to arrive at an answer.
Advantages of Agentic RAG
- Enhanced Reasoning Capabilities: By incorporating agents, RAG systems gain the ability to perform more complex reasoning tasks. Instead of simply retrieving and synthesizing information, the system can break down complex queries into sub-tasks, select appropriate tools (i.e., document agents and their functionalities), and execute actions to gather the necessary information.
- Handling Complex Queries: Agentic RAG systems can handle queries that go beyond simple question answering. They can tackle tasks like:
- Multi-Document Summarization: Synthesizing information from multiple documents to provide a comprehensive overview.
- Document Comparison: Analyzing and comparing the content of different documents to identify similarities or differences.
- Information Synthesis: Combining information from various sources to derive new insights.
- Improved Response Quality: By employing reasoning and tool selection, agentic RAG systems can generate more accurate, comprehensive, and insightful responses, overcoming the limitations of relying solely on retrieved text.
The Future of Agentic RAG
The integration of agents into RAG pipelines represents an exciting frontier in the development of more intelligent and capable information retrieval systems. As research in this area progresses, we can expect to see even more sophisticated approaches to leveraging agent-based reasoning and action within RAG frameworks.
Reference: https://youtu.be/TRjq7t2Ms5I?list=TLGGrRQYbcv1NwwzMDEwMjAyNA

Leave a reply to Understanding Production RAG Systems (Retrieval Augmented Generation) – Infinite Couch Cancel reply